Course Notes for CMU 16-831 Graduate Course on Robot Learning: Introduction to Robot Learning | Introduction to Robot Learning
Imitation Learning
MDP (Markov Decision process)
Definitions:
- : State space, : state at time
- : Action space, : action at time
- : Transition probability,
- : Reward function,
Goal: Learn a policy .
POMDP (Partially Observed MDP)
Additional Definitions:
- : Observation space, : observation at time
- : Observation model,
Goal: Learn a policy .
Imitation Learning
Idea
- collect expert data (observation/state and action pairs)
- Train a function to map observations/states to actions
Dataset Aggregation (DAgger)
-
Process:
- Start with expert demonstrations.
- Train policy via supervised learning.
- Run , query the expert to correct mistakes, and collect new data.
- Aggregate new and old data, retrain to create .
- Repeat the process iteratively.
-
Advantages:
- Reduces cascading errors.
- Provides theoretical regret guarantees.
-
Limitations:
- Requires frequent expert queries.
IL with Privileged Teachers
- It can be hard to directly learn the policy especially if is high-dimensional
Obtain a "privileged" teacher
- contains “ground truth” information that is not available to the “students”
- Then use to generate demonstrations for
Example
- Stage 1: learn a “privileged agent” from expert
- It knows ground truth state (traffic light, other vehicles’ pos/vel, etc)
- Stage 2: a sensorimotor student learns from this trained privileged agent
This is especially useful in simulation, because we know every variable’s value in sim. So the privileged teacher learns from that, but the student only learns from stuff it can directly see/measure.
- privileged teacher is usually trained by PPO
Variants
- Student learning in the latent space: Adapting Rapid Motor Adaptation for Bipedal Robots
- Student learning to predict rays: [2401.17583] Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
Deep Imitation Learning with Generative Modeling
What is the problem posed by generative modeling?
- Learn: learn a distribution that matches
- Sample: Generate novel data so that
For robotics, we want our to be from experts.
There are three leading approaches:
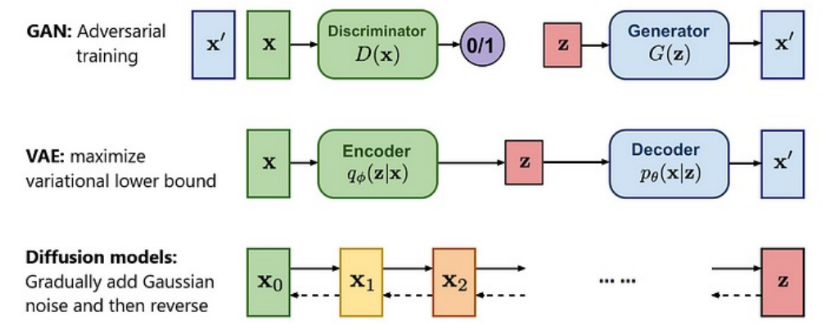
GAN + Imitation Learning Generative Adversarial Imitation Learning (GAIL)
- Sample trajectory from students
- Update the discriminator, which is aimed at classifying the teacher and the student
- Train the student policy which aims to minimize the discriminator’s accuracy
VAE + IL Action Chunking with Transformers
- Based on CVAE (conditional VAE)
- Encoder: expert action sequence + observation → latent
- Decoder: latent + more observation → action sequence prediction
- Key: action chunking + temporal ensemble
Diffusion + IL Diffusion Policy
Model-Free RL
See An Overview of Deep Reinforcement Learning.
Model-Based RL
Offline RL
Bandits and Exploration
Robot Simulation & Sim2Real
Train in simulation, deploy in real world (with real-time adaptation)
Why simulators for robot learning?
- most RL-based algos are very sample inefficient
- They are cheap/fast/scalable
Problems of Sim2Real
- non-parametric mismatches (simulator doesn’t consider some effects at all)
- complex aerodynamics, fluid dynamics, tire dynamics, etc
- Parametric mismatches (simulator uses different parameters than real)
- robot mass/friction,etc
Domain Randomization
- Randomize in
- Train a single RL policy that works for many
- Approximation of robust control
Learning to Adapt
- Randomize in
- Train an adaptive RL policy that works for many
- approximation of adaptive control
- Issue! is often unknown in real
- Solution! Learning from a privileged teacher
- Sim: First Train a teacher policy with privileged information
- Sim: Student policy learns from
- Real: Deploy student policy
- Basically an Imitation Learning problem
Safe Robot Learning
Multi-task and Adaptive Robot Learning
Foundation Models for Robotics
A more comprehensive list: JeffreyYH/Awesome-Generalist-Robots-via-Foundation-Models: Paper list in the survey paper: Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
![[Pasted image 20241228225953.png|]]
- VLMs for Robotic Perception
- CLIport
- GeFF
- LLMs for Task Planning
- SayCan
- LLMs for Action Generation
- Reward Generation: Language to Rewards for Robotic Skill Synthesis
- Robotics Foundation Models
- VLAs
Future Directions
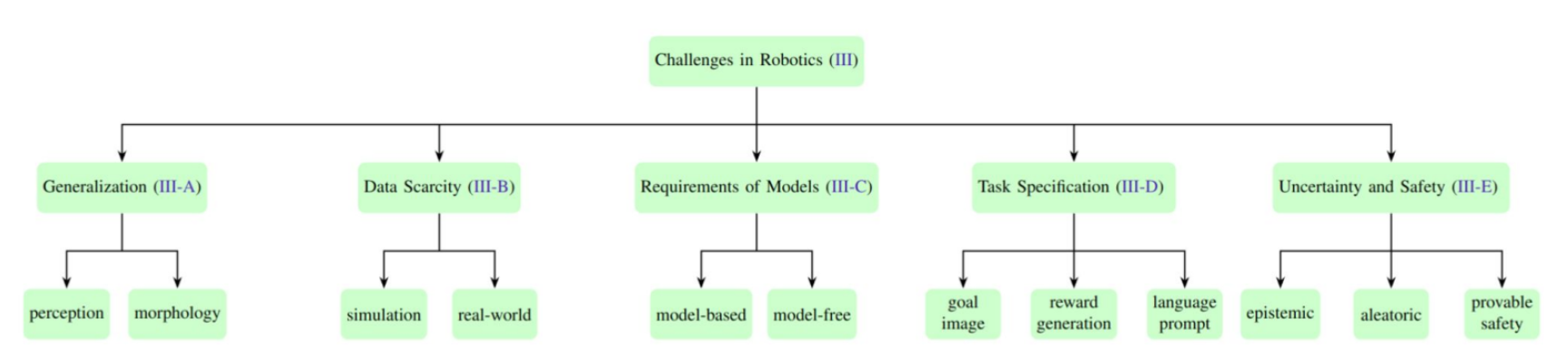
- Improving Simulations and Sim2Real
- LLM for Reward Design with Eureka
- Doing imitation learning
- No simulator. Collect data from real → learn a model → design a policy → deploy
- Meta-learned dynamics model + online adaptive control